Last updated on June 21, 2021
引言
这篇文章介绍了Kubernetes的基本概念和核心模型,如果你想简单了解下Kubernetes 相信读完本文你会对整体有个大概认知。如果你读完发现你并没有做一点,那是我写的不好……
kubernetes 是一个应用编排器,用来编排容器化的云原生的微服务应用。这句话提到以下术语
– 编排器
编排器是一个用来部署和管理应用的系统。 kubernetes 可以帮我们部署应用,根据需要自动扩展, 自适应恢复, 0宕机升级和回滚。
- 容器化(集装箱化)的应用
容器化的应用就是可以在容器里运行的应用
1980-1990 应用跑在物理机上, 2000-2010 应用跑在虚拟机上, 当前应用跑在云原生的容器上。 -
云原生的应用
云原生的应用指被设计满足现代商业需求的可以自动扩展,自动恢复,升级回滚的应用,这些应用可以跑在kubernetes上。
换句话来说,kubernetes 部署和管理那些可以被打包成可以在容器中运行的应用,这些应用以云原生的微服务的方式被构建以满足现代商业自动扩展,自适应恢复,在线升级的需求。
kubernetes 基本概念
总体来讲kubernetes 分为2个部分,第一kubernetes 是一个用来运行应用的集群, 第二kubernetes 是一个可以编排云原生微服务的编排器。
kubernetes 集群由masters 和 nodes 组成。
Master
kubernetes master 由一些系列系统服务组成,这些系统服务组成了集群的控制层面(Control Plane)。 这些系统服务包括:API server, Cluster Store, Controller Manager, Scheduler。

– API Server
API Server 是Kubernetes 的中枢,所有组件间的通信都要通过API Server。 API Server 开放了RESTful API 允许客户通过HTTPS 上传 YAML 配置文件,这些YAML 配置文件有时也称作manifest 描述了应用期望的状态,比如使用哪一个image,暴露哪个端口,使用多少个Pod。
- Cluster Store
Cluster store 是控制层绵中唯一有状态的组件, 它负责把整个集群的配置和状态进行持久化, 是集群中一个非常关键的组件,没有cluster store 就没有cluster。
当前kubernetes的cluster store是基于一个非常流行的分布式数据库–etcd。 etcd 使用RAFT 算法来保证一致性。
- Controller Manager
Controller Manager 实现了后台所有的用来监控和响应事件的轮询。它管理着kubernetes中所有的controller,这意味着controller manager 创建所有独立的控制轮询并监控它们。
这些控制轮询包括: node controller, endpoints controller, replicaset controller。 每一个controller 作为后台的一个监控轮询持续的监控着API Server的变化, 以确保
应用当前的状态和需要的状态保持一致。
- Scheduler
Scheduler 作为一个调度系统, 监测API Server 以便创建新的任务,并把这些任务分配给合适的健康节点。主要功能是根据相关条件找出合适的健康节点,比如节点是否用足够的可用资源,是否已经拥有指定的镜像等。
kubernetes master 负责运行集群的所有控制层面的服务。
Nodes
Nodes 是kubernetes 集群的工作节点,负责以下3件事:
(1)监控API Server是否分配了任务
(2)执行分配的任务
(3)通过API Server 向控制层面报告结果
一个Node包含3个主要的组件 Kubelet, Container Runtime 和 Network Proxy:
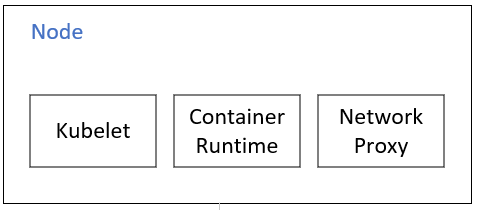
- Kubelet
kubelet 是kubernetes的一个代理(agent),运行在每一个node上,当kubernetes集群新加一个node时,一个进程会在这个节点安装kubelet agent,通过kubelet 向cluster 注册节点。
kubelet最主要的一个工作是监测API server分配的任务,执行任务,并向控制层面报告状态。 如果kubelet 不能执行分配的任务,那么kubelet把不能执行的信息报告给控制层面,并由控制层面决定采取何种行动。换句话说,当一个kubelet不能执行分配的任务时,kubelet 并不负责找到一个可以执行此任务的node, 它只是向控制层面报告,由控制层面决定如何处理。 -
Container Runtime
Kubelet 需要container runtime 来处理拉取镜像,启动和停止容器的任务。最初Kubeneter 使用Docker作为原生的container runtime, 现在Kubenetes已经通过开放一个统一的接口Container Runtime Interface(CRI)支持第三方Container Runtime。这是一种可插拔的模型,任何实现了CRI 的container runtime 都可以被Kubenetes使用。
默认情况下kubenetes 使用 containerd runtime作为 container runtime。 containerd 是由Docker捐赠给CNCF的。
- Network Proxy(Kube-proxy)
kube-proxy 运行在集群的每一个node上,负责集群内部的网络相关事务。比如确保每一个node都有自己独立的IP地址,负责实现集群内部的 IPTABLES 或IPVS 规则以便处理Pod网络的路由或者负载均衡。 -
Kubenetes DNS
除了上面介绍的控制层面和Node相关的组件,Kubenetes 集群还有一个 DNS 服务。 这个DNS 服务有一个静态的IP地址,这个地址以hard code的形式写在每一个Pod里。
因为是固定的IP地址,所以运行在Pod中的每一个服务都可以自动地把自己注册到DNS 服务中,这样集群的每一个组件都可以通过服务名字访问服务。
如何使用kubenetes 部署应用
使用kubenetes 部署应用需要3个步骤:
(1)把应用容器化。 开发完应用后需要把应用做成一个容器镜像,容器化后的应用才能在container runtime中运行
(2)封装一个Pod。 Pod是kubenetes的概念,是对Container的封装,是最小的部署单元。
(3)通过声明式的manifest (Declarative mainfest)文件部署这个Pod到Kubenetes 集群中。
这个声明式的manifest通过声明式模型(Declarative model)说明了这个应用需要的状态(desired state),比如使用哪个image, 有多少个备份,监听哪一个端口等等。 当这个文件被发送给API Server后,Kubenetes 会把它存在集群存储仓库中作为这个应用的声明的需要的状态(desired state),并持续监听这个应用的当前状态((current state)和声明的需要的状态(desired state),一旦出现状态不一致就会采取相关行动确保应用当前状态和声明的需要的状态一致。
Kubenetes 中的模型
Kubenetes 中有几个重要的模型: Pods, Deployments, Services, storage 和 ConfigMap。
这里我们先简单介绍下相关度非常高的Pods, Deployments和Services.
Pods
Pod是kubernetes中的最小单元就像容器对于docker一样。 Kubernetes是管理容器化的应用的,但是在kubernetes中并不能直接运行一个容器,容器必须被包含在一个Pod中,kubernetes运行的最小单位是Pod。
那么Pod和容器的关系是什么样的呢?
通常情况下一个Pod只包含一个容器,但是也有一些高级用例一个Pod可以运行多个container。Pod只是一个单独的运行容器的环境(environment),Pod本身不运行任何东西。Pod内的容器共享Pod中的环境,包括内存,数据卷,网络和IPC(interprocess communication) 命名空间(namespace)等。举个例子,Pod中的所有容器共享Pod的IP地址。

Pod内容器间可以用localhost下的不同端口来通信。

Pod是kubernetes最小的扩展单元,是最小的安排对象。 这句话意味着,kubernetes通过增加或删除Pod的方式支持应用的扩展,kubernetes不支持在一个创建好的Pod中增加或删除容器。
除此之外,Pod的部署是一个原子操作,这意味着只有Pod中的所有container都是运行状态,这个Pod才算可以对外提供服务。
Pod是必定是会死掉的,而且当一个Pod死掉(结束运行)后,只能创建一个新的Pod。即使这个新的Pod提供同样的服务,但是他的IP和ID已经改变。 这个特性也要求在设计应用时应该保证应用和特定的Pod实例解耦。
Deployments, DaemonSets and StatefulSet
Deployments 是kubernetes中一个高层次的对象,它封装具体的Pod并且支持添加更多特性比如自动扩展,0宕机更新和版本回滚等。
Deployments, DaemonSets and StatefulSet背后实现了一个控制器和一个监控循环,这个监控会一直观察kubernetes集群的状态确保应用当前状态和要求的状态一致。 当一个Pod死掉之后,它负责因创建一个新的Pod,这正是kubernetes的精髓。
Services
正如上面提到的,当通过Deployments, DaemonSets或StatefulSet 部署Pod时,当一个Pod意外死掉后,它们会创建新的Pod来代替他们,但是这个时候新的Pod的IP 已经变了。那么如果外部客户只能通过IP访问服务,原先工作的IP变了,那么客户就会访问服务失败。
Services被用来解决这个问题。 Service通过提供稳定的名字和IP地址来为Pod集合提供可一个稳定的网络,并且可以充当负载均衡器。这句翻译是不是很拗口? 就是Service这个Kubernetes中定义的对象包含一个不变的名字和IP地址。Service的工作流程如下图所示。图中展示了微服务uploader通过Services 和微服务renderer进行通信。 Service提供了一个稳定的名字和IP,并负责把请求以负载均衡的方式路由到两个Pod。

Services能够自动发现新加入的Pod并更新自己,当有Pod死掉后,Services会移除相关的Pod,这些死掉的Pod不会再收到流量。
需要注意的是Services工作在网络中的TCP和UDP 层。(Http工作在应用层哦)
Services是如何自动发现新加入的Pod的?
Services通过标签和标签选择器来发现Pod。 Pod在声明时可以声明相关的标签,Services在声明时可以声明标签选择器,Services为所有满足标签选择器的健康Pod提供网络服务。
如下图所示,有3个Pod其中2个Pod能被Services的标签选择器选中。

总结
以上就包含了Kubernetes的大部分内容。通过这篇文章大家可以大概知道Kubernetes是做什么的,怎么做的以及Kubernetes 有哪些核心模型。
接下来的文章会结合实际案例,具体分析下Kubernetes 模型的细节。
Comments are closed.